Engineering Fast Data Grids: Lessons from Optimizing Ignite UI for 1M+ Data Records
Grid performance isn’t just about speed here. It's about consistency under heavy data load. When a grid freezes during data operations, it feels slow and unreliable. In real-time decision-making workflows, that unreliability becomes a liability.
For developers building finance, banking, ERP, and other data-heavy systems, the data grid is often the primary performance boundary – the “hot loop” where sorting and filtering across large datasets compete for main-thread time. In these cases, small inefficiencies quickly become user-visible and break interaction.
But we found a solution. This post will demonstrate how we optimized sorting and filtering to keep Ignite UI fast at 1M+ rows across frameworks (Angular, React, Blazor, Web Components). We’ll focus on the concrete data grid sorting and filtering changes that worked and the ones that didn’t.
Let’s see what we did.
The Reality Before Optimization: Where Things Started to Break
Every performance problem starts the same way – an architecture that was reasonable at one scale becomes a bottleneck at another. Features like Ignite UI’s sorting, grouping, and filtering were no exception.
Sorting: The Hidden Cost of Value Resolution
The core sorting pipeline worked recursively, processing each sorting expression in sequence. For multi-column sorting, after sorting by the primary expression, it grouped equal-value records and recursively sorted each group by the next expression. Clean, correct, and completely reasonable for small datasets.
The problem was the value resolver.
Because the grid supports multiple column data types – date portions of Date objects, time portions of Date objects, strings, numbers, hierarchical key-value objects – every value comparison required resolving the field value at runtime. The value resolver handled path traversal, date parsing, and time normalization, number parsing, all on every single comparison. It was called twice per comparison operation – once for each side:
compare(recordA, recordB):
valA = resolveValue(recordA, field) // path traversal + date parsing + type coercion
valB = resolveValue(recordB, field) // same cost, every single comparison
return compareValues(valA, valB)
For a standard comparison sort, that’s comparisons, with the resolver called twice per comparison. At 100K rows: 3.4 million resolver calls per sorted column. At 1M rows: 40 million resolver calls. Each one doing runtime path resolution and potential date parsing, with no caching between calls.
But the sort comparer wasn’t the only place the value resolver was invoked. For multi-column sorting, after sorting by expression i, the algorithm needed to find groups of equal values before sorting by expression i+1. This group detection iterated over every record, calling the resolver once per record – an additional pass on top of the sort.
So, for a two-column sort over 1M rows, the value resolver was invoked on the order of + times for the first expression alone – before the second expression was even touched.
- At 10K rows: imperceptible.
- At 100K rows: a noticeable lag, but tolerable.
- At 1M rows: the main thread froze for several seconds. In rare cases, deep recursive call stacks caused a stack overflow.
Grouping: Same Root, Compounded Cost
Grouping extends the same recursive pattern and requires the data to be sorted first. This way, the resolver cost was paid once during sort, then again during group boundary detection.
groupDataRecursive(data, state, level):
while i < data.length:
group = groupByExpression(data, i, expressions[level])
// resolver called once for group anchor value
// resolver called again for every subsequent record in the group
if level < expressions.length - 1:
groupDataRecursive(group, state, level + 1) // recurse into subgroups
else:
result = result.concat(...) // array allocation per group boundary
Two compounding costs here:
- The value resolver was invoked repeatedly for values that had already been resolved during sorting, with no shared cache between the two phases.
- Each group boundary produced new arrays via concat and slice, i.e. allocations that added measurable GC pressure at scale across potentially thousands of groups
Excel-Style Filtering: Paying the Full Cost Twice
Quick filtering and advanced filtering were fast. Excel-style filtering (ESF) was not, and the reason was architectural.
When the ESF dialog opened, it triggered a full initialization pipeline synchronously on the main thread:

The dialog’s opening animation was effectively paused until all four operations were completed. With large datasets this was a user-visible freeze, the dialog didn’t appear janky. It simply didn’t appear at all until the pipeline finished.
The more critical problem: this entire pipeline ran again when the user clicked Apply even though the underlying data hadn’t changed between open and apply:
onApplyClick():
filter data
re-run full ESF initialization // same 4 steps, same cost, same blocking
close dialog
This is why ESF was significantly slower than advanced filtering in practice: it was doing the same work twice per operation, blocking the main thread both times.
Why “Just Virtualize More” Wasn’t the Answer
Virtualization ensures only the number of visible rows to be rendered as DOM nodes regardless of dataset size. That’s what makes scrolling through 1M rows feasible. But the data operations that determine what those rows contain – sorting, filtering, grouping – run against the full dataset every time. Virtualization can’t help there. Every bottleneck above lived in the data pipeline, before a single row was rendered:
- The resolver was called + times per sort expression, regardless of how many rows were visible.
- Grouping paid the resolution cost again on top of sorting, plus concat/slice allocation pressure across group boundaries.
- ESF’s entire initialization pipeline iterated the full dataset synchronously, on open and again on apply.
Virtualization is the right tool for making large grids scrollable. It does nothing for making sorting, filtering, and grouping fast. Those required a different type of fix.
Measuring the Problem: How We Benchmarked Grid Performance
Anecdotes like “it feels slow” and “it feels fast” are a starting point, not a diagnosis. To optimize with confidence, we needed reproducible numbers instead of impressions.
It’s tempting to rely on DevTools flame graphs or FPS counters to diagnose grid performance. But those measure the full rendering pipeline – change detection, DOM updates, layout, which can obscure that the time is actually spent in the data pipeline.
To pinpoint the algorithm cost specifically, we instrumented the sorting, grouping, and filtering logic directly using a lightweight wrapper around the native Performance API :
startMeasure(‘sorting’)
-> run sorting algorithm
getMeasures(‘sorting’) // returns the duration
This gave us sub-millisecond timing on algorithms in isolation without rendering noise or change detection overhead. Just the raw data pipeline cost. Worth noting: all numbers below were recorded in Angular dev mode. Production builds would be faster, but dev mode overhead is consistent across runs, so the relative differences hold.
The Datasets
Rows:
10K / 100K / 1,000,000
Columns:
string - names, categories (with duplicates)
number - IDs, prices, quantities (with duplicates)
date - formatted date strings (require parsing)
time - HH:mm:ss formatted strings (require parsing)
The presence of duplicate values in sort and group columns was intentional – it reflects realistic data distributions and directly impacts grouping cost, since more duplicate values mean more group boundary detections and deeper recursive calls. Date and time columns used formatted string representations. This is important for interpreting the results: every comparison involving these columns requires parsing the string into a comparable value at runtime.
Scenarios and Results
At 10K and 100K rows, most operations were acceptable. At 1 million rows, the picture changed dramatically:
| Scenario | Time (1M rows) |
| Single column sort – string | 3.38s |
| Single column sort – number | 1.50s |
| Multi-column sort – string → number | 3.88s |
| Grouping – single string column (sort + group) | 3.31s |
| Grouping algorithm only (after sort) | 0.50s |
| Grouping – two columns on grid load | 3.86s |
| Grouping – two columns (after sort) | 1.01s |
| ESF open – number column (15K unique values) | 1.60s |
| ESF open – date column (274 unique values) | 5.20s |
| ESF open – time column (86K unique values) | 6.60s |
| ESF apply – number column | 1.37s |
Reading the Numbers
Several patterns emerge immediately, and each one points directly at a specific architectural problem.
Sorting dominates grouping cost. The grouping algorithm alone took 0.50s. Full sort + group took 3.31s – a 6.6x difference. The grouping logic itself was never the bottleneck. Sorting was, and specifically the value resolver being called times inside the sort comparator.
String sorting is more than twice as slow as number sorting (3.38s vs 1.50s). Numbers compare with a simple subtraction. Strings go through the value resolver, potential normalization for case-insensitive sorts, and a string comparison. That difference compounds across ~20 million comparisons at 1M rows.
The ESF date anomaly is the most revealing data point. The date column had only 274 unique values – a tiny list compared to 15K in the number column. Yet opening the ESF dialog took 5.20s vs 1.60s for the number column. The culprit wasn’t iteration count. It was date parsing cost per item. The full dataset was iterated during ESF initialization, and every value went through string-to-date parsing. Fewer unique values didn’t help because the parsing happened across all records, not just the unique ones. The time column (6.60s with 86K unique values + time string parsing) confirms the same pattern: formatted string columns are expensive regardless of cardinality.
ESF open + ESF apply = the full cost paid twice. For a number column, the cheapest case – that’s 1.60s + 1.37s = ~3s of blocking per filter operation. For date or time columns the combined cost would be significantly worse.
The numbers confirmed what the architecture review suggested: the value resolver, the recursive grouping passes, and the ESF double-initialization were the bottlenecks. Now we had the data to prove it.
Optimization #1: Rethinking the Sorting Pipeline
With a clear baseline established, the focus shifted to the data pipeline itself. Three changes drove the majority of the improvement: applying the Schwartzian transform to sorting, refactoring multi-column sorting from recursive to iterative, and reworking the grouping algorithm to eliminate both recursion and redundant array allocations.
Fix #1: The Schwartzian Transform
The original sort comparator resolved field values inside the comparison function itself – meaning for every pair of records compared, the value resolver ran twice.
The Schwartzian transform is a classic optimization for expensive sort keys: resolve each value once upfront, sort on the cached values, then map back to the original records. This improves field resolution from to :
// Before: resolve inside comparator - O(n log n) resolver calls
sort(data, field):
data.sort((a, b) => compare(resolveValue(a), resolveValue(b)))
// After: Schwartzian transform - O(n) resolver calls
sort(data, field):
prepared = data.map(record => [record, resolveValue(record, field)]) // O(n) - resolve once
prepared.sort(([, valA], [, valB]) => compareValues(valA, valB)) // O(n log n) — compare only
return prepared.map(([record]) => record) // O(n) - unwrap
The comparer becomes a pure value comparison with no field resolution, no path traversal, no date parsing. For ignoreCase, the string normalization call moves into the map phase – resolved once per record, not once per comparison side.
For date and time columns, the impact is especially significant: string-to-date parsing moves from inside the hot comparer loop to a single upfront pass. At 1M rows that’s the difference between ~40 million parse calls and exactly 1 million, which is with a constant multiplier of 1, regardless of column type.
Fix #2: Iterative Multi-Column Sorting
The original multi-column sort was recursive: sort by expression 0, find same-value groups, recursively sort each group by expression 1, and so on. Correct, but with two problems: recursive call stack depth, and the value resolver being called again inside group detection for every record on every pass.
The new approach iterates backwards through expressions, which is a deliberate choice to maintain sort stability, matching the behavior of the original recursive implementation:
// Before: recursive
sortDataRecursive(data, expressions, index):
sort by expressions[index]
for each equal-value group:
sortDataRecursive(group, expressions, index + 1) // recursive
// After: iterative - reverse pass maintains stability
sortData(data, expressions):
for i = expressions.length - 1 down to 0:
data = expressions[i].strategy.sort(data) // iterative, no recursion
Iterating in reverse means the most significant sort key is applied last. It becomes the final tiebreaker, and the overall order remains stable. No recursive call stack, no intermediate group detection passes between expressions;, no additional resolver calls. The Schwartzian transform applies independently to each expression pass.
Fix #3: Iterative Grouping with a Stack
The grouping algorithm had two independent cost sources: the recursive call structure and concat/slice array allocations at every group boundary. Both were addressed together.
// Before: recursive with concat/slice
groupDataRecursive(data, state, level):
group = data.slice(start, end) // allocation per group
result = result.concat(groupRow, group) // allocation per group
groupDataRecursive(group, state, level + 1) // recursive
// After: iterative with explicit stack + direct push
groupData(data, state):
stack = [{ data, level: 0 }]
while stack.length > 0:
{ data, level } = stack.pop()
for each group boundary in data:
result.push(groupRow) // no intermediate allocation
result.push(...groupRecords) // no intermediate allocation
if level < expressions.length - 1:
stack.push({ data: groupRecords, level: level + 1 })
Array pre-allocation wasn’t feasible here because the number of groups isn’t known upfront. But switching from concat/slice to direct push eliminated intermediate array allocations at every group boundary. At scale, across potentially thousands of group boundaries, this made a measurable difference in both execution time and GC pressure.
The results
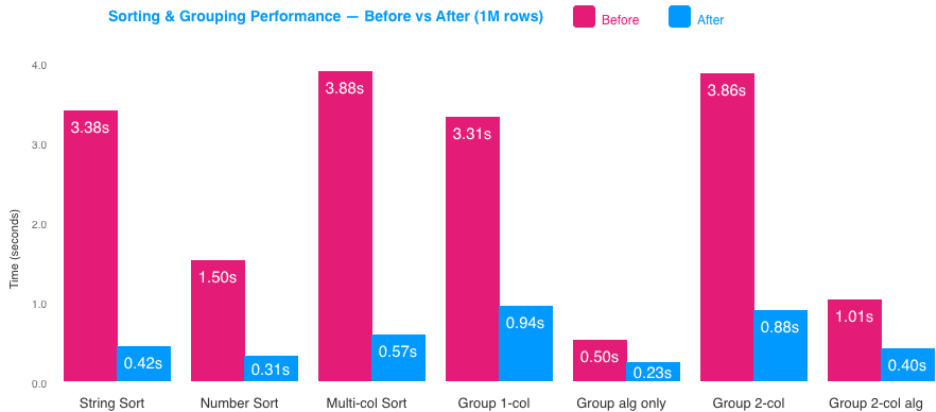
Raw milliseconds tell one part of the story. The more important metric is perceived responsiveness:
- A single-column string sort at 1M rows went from 3.38s – a visible, jarring freeze – to 0.42s, imperceptible to most users
- Multi-column sort dropped from 3.88s to 0.57s – users applying sequential sorts no longer experience compounding delays
- Two-column grouping on grid load went from 3.86s to 0.88s – the grid feels ready almost immediately
The gains compound in real usage: a user who sorts, then groups, then re-sorts is no longer waiting several seconds for each of those operations. The pipeline runs fast enough that interaction feels continuous rather than punctuated by freezes.
Optimization #2: Excel-Style Filtering at Scale
Sorting and grouping were the most visible bottlenecks, but Excel-style filtering had its own set of problems. Quick filtering and advanced filtering operate on the data directly: a predicate runs against each record and returns a match. Simple, linear, predictable.
Excel-style filtering is different. Before the dialog can show anything, it needs to build a complete picture of the data with every unique value in the column, formatted for display, sorted, and cross-referenced against the current filter state. That’s not just a filtering operation. That’s a full data pipeline, and it ran synchronously on the main thread every time the dialog opens.
As mentioned above the original Excel-style filtering initialization did four sequential passes over the data:
- Filter the dataset if there are applied filters beforehand – pass
- Sort the filtered values –
- Extract labels + format values – pass
- Deduplicate -> build unique items list – pass
The Apply re-initialization was the most wasteful part: the underlying data hadn’t changed between open and apply, but the entire pipeline ran again from scratch regardless.
Beyond the double cost, the pipeline itself had an inefficiency: steps 2, 3, and 4 were all operating on the full filtered dataset. Sorting happened before deduplication, meaning the grid was sorting potentially millions of records when it only needed to sort the unique values. Label extraction and deduplication were also separate passes over the same data, visiting every value twice unnecessarily.
The Date and Time Anomaly
The inefficiency was most visible with date and time columns. From the benchmarks in Measuring the Problem:
| Column | Unique values | ESF open time |
| Number | 15k | 1.60s |
| Date | 274 | 5.20s |
| Time | 86k | 6.60s |
The date column had 274 unique values – far fewer than the number column’s 15K – yet took 3× longer to open. The reason: label extraction and value formatting involved date parsing across the entire dataset, not just the unique values. Every record was visited, and every visit triggered string-to-date conversion. Fewer unique values didn’t help because the parsing happened during the full-data pass, not after deduplication.
Fix #1: Eliminate the Double Initialization
The most impactful change was structural: ESF no longer re-initializes on Apply. The unique values list built on open is reused directly when the user clicks Apply. The second full pipeline run is gone entirely.
// Before
onApplyClick():
re-run full ESF initialization // O(n) - redundant
close dialog
// After
onApplyClick():
apply filter using existing list // O(1) - list already built
close dialog
Fix #2: Single-Pass Deduplication with Deferred Sorting
The second change restructured the pipeline entirely, collapsing label extraction and deduplication into a single pass, then sorting only the deduplicated result:
// Before: separate passes
filteredData → sort → extract labels (pass 1) → deduplicate (pass 2)
// After: deduplicate in single pass → sort unique list only
filteredData (n records)
→ single pass:
resolve + normalize + deduplicate inline // O(n), parse only for new unique values
→ unique list (m items)
→ sort unique list // O(m log m) where m <= n
Two compounding improvements here:
- Label formatting and date parsing now only run for unique values, not for every record in the dataset. For a date column with 274 unique values in a 1M row dataset, that’s the difference between 1M parse calls and 274.
- Sorting now operates over the deduplicated list, not the full filtered dataset. At 274 unique values, sorting is effectively instantaneous. Even for the time column with 86K unique values, sorting 86K items is orders of magnitude cheaper than sorting 1M – and since each comparison in that sort involves a time string parse, shrinking the sort input compounds the savings further.
Fix #3: Non-Blocking Dialog Open
The third change addressed perceived performance directly: the dialog now opens immediately, before the data pipeline runs. A loading indicator is shown while initialization completes. This means the UI is never frozen waiting for a dialog that hasn’t appeared yet. Even if initialization takes time, the user sees immediate feedback – the dialog is open and something is happening.
Fix #4: Debounced Quick Filtering
A smaller but meaningful improvement on the quick filtering side: previously, the filtering pipe triggered on every keystroke, meaning a user typing “Finance” would trigger 7 filter operations in rapid succession, each one iterating the full dataset.
// Before: filter on every keystroke input: "F" → filter // O(n) input: "Fi" → filter // O(n) input: "Fin" → filter // O(n) ... // After: debounced input: "F", "Fi", "Fin", "Fina", "Finan", "Financ", "Finance" → pause detected → filter once // O(n) - only when user stops typing
For large datasets, this alone reduces the number of main-thread filter operations for a typical search from 5–10 down to 1–2.
The Results

The ESF apply number is particularly significant: at 90ms, it’s now in the same performance range as quick filtering and advanced filtering. The three filtering modes are now cost-comparable for the first time.
What This Means in Practice
- The ESF dialog appears immediately on click. No more waiting for a dialog that doesn’t show up.
- The overall time for data to load inside the ESF dialog is faster across all column types. Users spend less time staring at a loading indicator even when the dataset is large.
- Applying a filter no longer repeats the full initialization cost. It’s effectively free compared to before.
- Quick filtering no longer hammers the main thread on fast typing. Debouncing ensures the pipeline runs only when the user has finished or paused.
Why These Changes Work Across Frameworks
The performance improvements covered above were made in the Angular codebase. But they don’t stay there.
One Core, Multiple Frameworks
Ignite UI’s grid is built in Angular – usable directly as a native Angular component with full access to Angular’s template syntax, DI system, and change detection. It is also packaged as a Web Component using Angular Elements, making it available outside Angular entirely. React and Blazor consume that Web Component through thin framework-specific wrappers that bridge the custom element’s API into React props and Blazor parameters respectively.
The data pipeline – sorting, grouping, filtering – lives entirely in the Angular base. Angular Elements packages it into the Web Component as-is. React and Blazor never touch it. Every algorithmic improvement made in the Angular codebase propagates through the full chain automatically. It’s worth being precise about what “wrapper” means here. It’s a thin integration layer, not a reimplementation.
Why the Algorithm Improvements Are Framework-Agnostic
The Schwartzian transform, the iterative grouping stack, and the single-pass ESF deduplication are pure data operations. They take an array in and return a transformed array out. They have no knowledge of Angular’s change detection, React’s reconciler, or Blazor’s render tree – and that’s precisely why they propagate so cleanly across all four platforms.
The improvements are JavaScript engine gains:
- Fewer resolver calls per sort operation.
- Fewer intermediate array allocations per group boundary.
- Less GC pressure across the full pipeline.
- Shorter main thread blocking time on every data operation.
None of these are framework concepts. A faster sort improves performance regardless of whether the result is rendered by Angular, React, Web Components, or Blazor because the optimization occurs in the data layer before the UI framework renders it.
For developers evaluating which grid to use: the performance story is the same across frameworks because the engine is the same across frameworks. The numbers in this post aren’t Angular numbers. They’re data pipeline numbers, and the data pipeline is shared.
What This Means for Enterprise Teams
Engineering performance wins are easy to measure in milliseconds. Their business impact is harder to quantify but far more significant, especially at enterprise scale, where data grids aren’t decorative UI elements but the primary interface through which analysts, traders, and operations teams do their work.
Performance issues in data grids generate a specific and frustrating category of support tickets: ones that are hard to reproduce, hard to diagnose, and hard to close. “The grid freezes when I sort” is not a bug with a stack trace. It’s a symptom of a pipeline that blocks the main thread for several seconds under real-world data volumes.
Ignite UI supports remote data binding with sorting and filtering that can be delegated to a server rather than executed client-side. For teams that adopted remote operations primarily because client-side performance was inadequate, these optimizations change the calculus. Client-side sorting at 1M rows now completes in under half a second. For many enterprise datasets that previously pushed teams toward server-side delegation, the client-side pipeline is now fast enough to reconsider that decision.
In enterprise environments – particularly financial services – perceived responsiveness directly influences platform adoption. Moving a sort from 3.38s to 0.42s isn’t just an 8× improvement in isolation. It’s the difference between an interaction that interrupts a workflow and one that doesn’t register as a delay at all. That distinction matters when an end user is deciding whether the tool is worth using.
Lessons Learned: What We’d Do Again (and Differently)
The before and after numbers in this post are clean. The process that produced them wasn’t. Here’s what that process actually looked like.
Nothing Was Guaranteed Upfront
Going into this work, there was no certainty that any of these optimizations would produce meaningful results. The Schwartzian transform is a well-known technique. However, “well-known” doesn’t mean “guaranteed to help in this context.” The iterative grouping stack looked promising on paper, but recursive-to-iterative refactors have a history of introducing subtle edge cases that only appear under specific data shapes.
The approach was deliberately incremental: tackling one problem at a time, measure, then deciding whether to continue. The sorting pipeline came first. When the numbers came back – 3.38s to 0.42s on a string sort – it validated the direction and justified continuing into grouping and filtering. If the first optimization had shown marginal gains, the strategy would have changed.
This matters because performance work is often planned as if the outcomes are known in advance. They aren’t. The right posture is hypothesis, measurement, decision, repeat.
The Memory Trade-off
The Schwartzian transform isn’t free. It allocates an intermediate array of [record, value] pairs upfront – one entry per record. At 1M rows, that’s a non-trivial memory overhead before the sort even begins.
This was a conscious trade-off: accept higher peak memory usage in exchange for eliminating resolver calls. For the use cases this library targets, i.e. enterprise grids running in modern browsers on capable hardware, the speed gains are significant, and the memory cost is acceptable.
But it’s worth naming explicitly: if memory-constrained environments ever become a primary target, the Schwartzian transform would need to be revisited. Speed and memory pull in opposite directions here, and the current implementation chose speed.
Benchmarks Must Reflect Real Usage
The benchmark suite for this work used synthetic datasets at 1M rows (generated records with controlled column types and value distributions.) That’s the right starting point for isolating algorithmic performance, but it has a ceiling.
The two issues that actually prompted this work came from a real customer: ESF dialog open time and ESF apply time were reported as blocking problems in production. When those tickets arrived, the synthetic benchmarks confirmed the problem. The problem existed before the ticket. It took a real-world usage pattern to surface it.
The lesson is straightforward: synthetic benchmarks are good at measuring scenarios you already know to test. Customer data finds the ones you didn’t think to include. Both are necessary, and the benchmark suite should evolve to incorporate real-world usage patterns as they surface, not just synthetic worst cases.
Performance Work Is Never Done
The improvements in this post are real and significant. They’re also a snapshot. The data pipeline is faster today than it was six months ago. Six months from now, there are known areas, such as date parsing, virtualization, etc. that will look like the sorting pipeline looked before this work. They will be functional, but with room for improvement that hasn’t been addressed yet.
That’s not a failure of the current work. It’s the nature of performance engineering. The baseline moves, customer data volumes grow, and the definition of “fast enough” shifts with it. The value of this round of optimizations isn’t just the milliseconds saved. It’s the process established for finding and closing the next gap.
What’s Next for Ignite UI Grid Performance
The optimizations in this post represent one focused round of performance work and not a closing statement on the topic. Several areas are already in motion, and more are being actively explored.
What’s Already Improved
Virtualization performance has seen improvements alongside the sorting, grouping, and filtering work covered in this post. Row and column virtualization is the foundation that makes large dataset rendering feasible. All the improvements there compound with the data pipeline gains, meaning the grid is faster both at processing data and at rendering it.
What’s Still Being Worked On
Date parsing remains an area with known room for improvement. The sorting and ESF results for date and time columns are dramatically better than before, but they’re still slower than number columns in ways that trace back to how date strings are parsed. More targeted work on the parsing layer is the logical next step.
Bundle size is an ongoing focus. A faster grid that ships more JavaScript than necessary works against itself, particularly for teams where initial load time is as important as runtime performance. Reducing the footprint of the grid without sacrificing capability is a continuous balancing act.
Grid API refinement continues in parallel. It’s not a performance concern directly but connected to it. A cleaner API reduces the surface area where performance-sensitive code paths get invoked in unintended ways.
Runtime performance more broadly, including rendering cost, change detection pressure, interaction responsiveness under high-frequency updates, remains an open area of exploration. No specific claims, but it’s on the radar.
Share Your Feedback on Performance
Each performance improvement raises the baseline and expectations. What was once slow becomes fast, and new bottlenecks eventually appear.
That’s why we value useful feedback from real-world usage. If you’re using Ignite UI grids in production and hit performance issues, open an issue on GitHub. Real scenarios and reproducible cases help us identify the next opportunities for improvement.
Closing: Performance as a Promise, Not a Bullet Point
Every grid library lists performance as a feature. “Handles millions of rows” appears in comparison tables alongside other features like a checkbox, not a commitment.
There is a difference between a grid that technically handles large datasets and one that handles them without making users wait. That difference doesn’t show up in a feature list. It shows up when a user clicks a column header or opens a filter dialog and either gets an immediate response or watches the UI freeze.
The work in this post was driven by that distinction. Not by a marketing requirement – by a real customer hitting real performance walls, and by the recognition that “it works” and “it’s fast” are not the same claim. The Schwartzian transform, the iterative grouping stack, the single-pass ESF pipeline – none of it was obvious upfront, none of it was guaranteed to work, and all of it required measurement to justify.
Performance isn’t a feature you ship and move on from. It’s a continuous obligation to the developers and end users who depend on these components to do real work, at real scale, without the UI getting in the way.
We intend to keep meeting it.